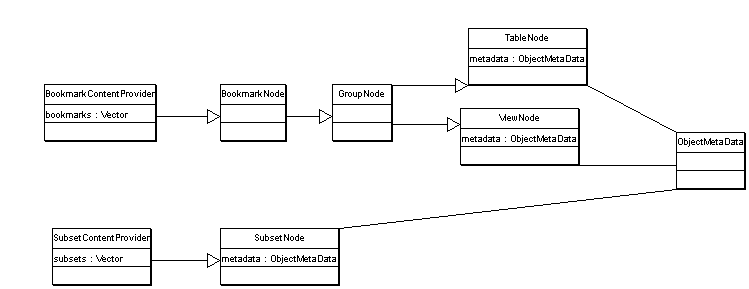
After loading the Quantum plug-in, the saved-state file (an xml file) is loaded up. Bookmarks are loaded into the BookmarkContentProvider and the SubsetContentProvider classes, where they are stored in the form of a vector of BookmarkNode and SubsetNode respectively.
A SubsetNode has a number of children, objects of class ObjectNode. Each ObjectNode has an ObjectMetaData instance that will hold the metadata (columns names, sizes and that stuff) of the table or view that it (the ObjectNode) references. That metadata is loaded from the saved-state file also on load-up of the plug-in (three hypen-words in a single-sentence, wow! :)
A BookmarkNode represents a connection with a database. It will be displayed by the BookmarView view. When you double-click on one of the bookmarks, the function MultiSQLServer.connect(current) willl be called. MultiSQLServer is a Singleton (a class that will have a single instance), so we can get the instance of it with MultiSQLServer.getInstance().
The connect() function will use the JDBC driver and connect to the database. After that, the BookmarkNode will have its con member assigned (not null). After the connection, the function that is answering your double-clicking (ConnectAction.run()), will try to get the tables, views, etc from that connection. To do that, it will call BookmarkView.refreshBookmarkData(), that will query the database. As the procedure to get the tables may be different for each database, the actual querying is delegated to another class SQLHelper, that will centralize that kind of procedures (the ones that depend on the type of the database). The called function in this case is getTableList(). SQLHelper is not a Singleton, although it could be, but we don't really need an instance because the functions are all static.
The getTableList() will try to get the tables from the function MultiSQLServer.listTables(), if the jdbc adapter of the bookmark is generic. listTables will ask the jdbc driver directly for the list of tables, using the DatabaseMetadata.getTables() call. If the adapter is not generic, it will use a SQL statement to get the list of table names. This SQL statement will be of course different in every database, so it will come from the DatabaseAdapter class.
The DatabaseAdapter class is the one where you should put all the functions that will be different for each database. Then for each database, you create an "adapter" class derived from DatabaseAdapter, and implement all the necessary abstract functions. So you get a proper adapter using DatabaseAdapter adapter = AdapterFactory.getInstance().getAdapter(current.getType()), and the returned adapter will have the proper type (always a derived type from DatabaseAdapter). Then calls to the adapter object will be redirected to the proper function.
The TableNode objects generated will have metadata, i.e. columns. That information is saved in an object of class ObjectMetaData in the TableNode object. This ObjectMetaData class is part of the metadata package, that has basically four classes:
MetaDataJDBCInterface : Basically takes care (through static functions) of passing the metadata from the jdbc driver to the ObjectMetadata class.
MetaDataXMLInterface : Handles interface between an ObjectMetaData and XML storage. It can write an existing metadata object to XML and generate a new ObjectMetaData from existing XML.
ObjectMetaData : The class that has all the metadata. Rather underdeveloped, one must add functions as needed. The metadata is saved in the form of StringMatrix objects.
StringMatrix : A matrix of strings. Saves the results from the jdbc driver, usually given as ResultSet objects, that are very similar in structure but sequential in nature (you access the records one at a time). The first line of the matrix are the names of the columns, and the rest hold the values.